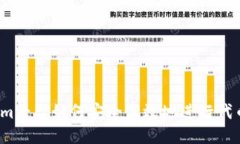
在加密货币的世界里,越来越多的人开始关注自动化交易的工具与策略,其中Tokenim作为一款相对新兴的自动打币工具...
TokenIM在自然语言处理的领域中扮演着重要的角色,特别是在助词恢复方面。助词是语言中不可或缺的组成部分,它们在句子中起到连接、表示关系和提供语法功能的作用。本文将深入探讨TokenIM助词恢复的原理、应用及其在实际场景中的运用,同时回答与之相关的五个问题,帮助用户更好地理解该技术的价值。
TokenIM是一款基于最新深度学习技术的人机交互平台,其主要功能之一是对文本中的缺失助词进行恢复。助词恢复的基本原理是依赖于大量的文本数据和上下文信息,通过机器学习模型训练,使其能够理解句子结构和语义关联。
在语言中,助词虽然在拼写上并不是必须的,但它们在意义上却起着至关重要的作用。TokenIM的助词恢复技术首先会分析输入的文本,识别句子的核心成分和上下文的关系,从而推测出缺失的助词。
机器学习算法在这个过程中发挥了重要作用,包括序列到序列模型(Seq2Seq)和长短期记忆网络(LSTM)等。这些模型能够捕捉文本中的长距离依赖关系,使得助词恢复更加准确。
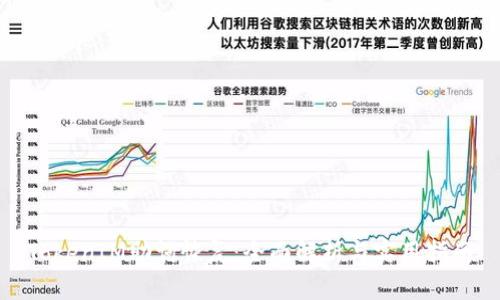
TokenIM在助词恢复方面的应用范围十分广泛,尤其是在以下几个方面表现尤为突出:
在了解TokenIM助词恢复的基本知识后,以下是常见的五个相关

助词恢复技术是指通过计算机算法,以补全文本中的缺失助词,确保语句表达准确完整的一种技术。它通过分析上下文中的信息,辨别出可能的助词并进行插入,确保句子结构和语义的严谨性。一般来说,助词恢复技术依赖于自然语言处理(NLP)的相关理论模型,通过大量的语言数据进行训练。
在助词恢复的过程中,最重要的就是上下文。计算机首先分析前后句的语法、逻辑关系,然后根据这些关系推测缺失的助词。例如,在中文语境中,如果有一句话“我喜欢____苹果”,计算机需要分析“我”和“喜欢”之间的关系,推测出缺失的助词是“的”,从而最终生成“我喜欢的苹果”。
TokenIM利用大量文本数据作为训练集,以实现助词恢复的模型训练。训练的数据可能包括书籍、文章、网络博客等多种形式的文本材料。这些文本在训练之前需要经过预处理,例如分词、去除停用词等,以适应算法的需求。
TokenIM通常使用深度学习中的序列到序列(Seq2Seq)模型,这是目前处理自然语言生成的主流方法。该模型通过编码器-解码器结构将输入文本进行编码,然后再解码生成完整的文本,在这个过程中的重要步骤就是对缺失助词的预测。
模型的训练需要多个迭代周期,通过不断调整参数,使系统的预测结果越来越接近真实的文本,最终实现对助词的准确恢复。训练完成后,模型还会接受额外的验证和测试,以确保其在不同语境下的适用性。
在助词恢复的过程中,TokenIM需要面对多种技术挑战:
当然,随着技术的发展,这些挑战正在逐步得到解决。TokenIM也会定期更新模型,提升其性能和适用性。
助词恢复在自然语言处理(NLP)中具有特别重要的地位,以下是该技术的几个主要影响:
因此,助词恢复不仅对具体技术实现具有深远意义,也为自然语言处理领域的各项应用提供了更为坚实的基础。
展望未来,TokenIM的助词恢复技术有几个可能的发展方向:
总之,TokenIM助词恢复的前景广阔,未来将为自然语言处理领域带来更多机遇和挑战。
通过以上内容的介绍,相信用户对TokenIM助词恢复有了更为深入的理解。如果有任何相关的问题或需求,可以随时进行咨询,获取进一步的帮助和支持。


在加密货币的世界里,越来越多的人开始关注自动化交易的工具与策略,其中Tokenim作为一款相对新兴的自动打币工具...

随着区块链技术的不断发展,数字资产的管理逐渐成为大众关注的焦点。在众多数字钱包中,IM多前钱包因其安全性和...
在数字货币日益流行的时代,imToken作为一款知名的数字资产钱包,为用户提供方便的交易和资产管理能力。那么,如...
--- 引言 在加密货币的世界中,提币是一个重要的操作,尤其是在交易所如Tokenim上。用户频繁地进行买卖操作,但在...